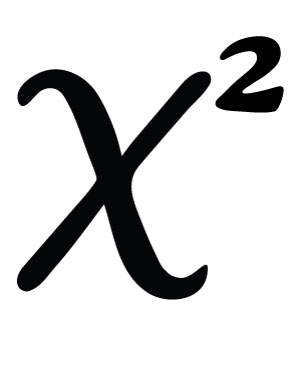

The Music industry is huge.
The global recorded music industry reached $16.1bn in 2016, and up 7% YoY. The digital music industry represents 33% of total recorded music market share. Streaming revenue reached $5.4bn last year, growing 57% year-on-year and up from $3.5bn in 2015. Subscribers to streaming services grew by 38.8bn, with Spotify accounting for 43% of the 106.3m worldwide subscribers. Midia predicts that number will increase by 40.3m by the end of 2017.
It is estimated that Spotify and Apple Music has access to over 30 million songs. As the number of subscribers increase, it becomes ever more important to classify song genres correctly, to ensure that the user experience is so good, that
- The subscriber keeps enjoying the music, perhaps even more so than buying music through traditional methods via recommending more material that is of interest
- The subscriber is not lost to a competitor who might have a similar catalogue of music
The question is, if you dont have access to genre information from the record label or artist, how do you classify songs effectively? Added to this is the problem that artists can theoretically cross genres depending on the type of song they have chosen to record. Doing this manually would be an arduous task, even though it may be made more interesting by the fact that you would be able to listen to a lot of music to get your work done! There is the added problem that there is significant potential for human error and a high degree of subjectivity.
Can Machine Learning do better?
It is perhaps strong to suggest that computer generated genre classification of music would be mistake free, but it doesn’t mean that it cant be more efficient than manually entering the classification for 30 million songs. The aim of this project is to see if it is possible to use machine learning to classify music based on the features of the track, such as intensity, instruments used, vocals etc. Techniques like this would be extremely beneficial not only to those in the music industry, but to any organization that needs to classify groups within a large dataset.
Where do we get the data?
There are very few datasets available for analyzing music, mainly due to copyright restrictions. The main dataset available is the million song dataset, but the size is 300gb, and no genre information is associated with this. Some have tried to create sample sets which have genres, but no features to analyze along with it, and to make matters worse, they all have their own ids! Fortunately, there are sources that have tried to link the various id’s together, and I will be using this to create a new dataset using the spotify api, and linking the features to the genres provided by the other datasets, and artist information from the million song dataset.
Thats it for now, but find out more in part 2 of this series.
Alex Cave